


import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)최종코드는 제일 아래 있습니다.

크롤링 구상 순서
1. 웹에서 게시물을 접근하는 방법 구현
2. 게시물에서 데이터를 크롤링하는 방법 구현
웹-> 게시물 -> 데이터 순으로 접근
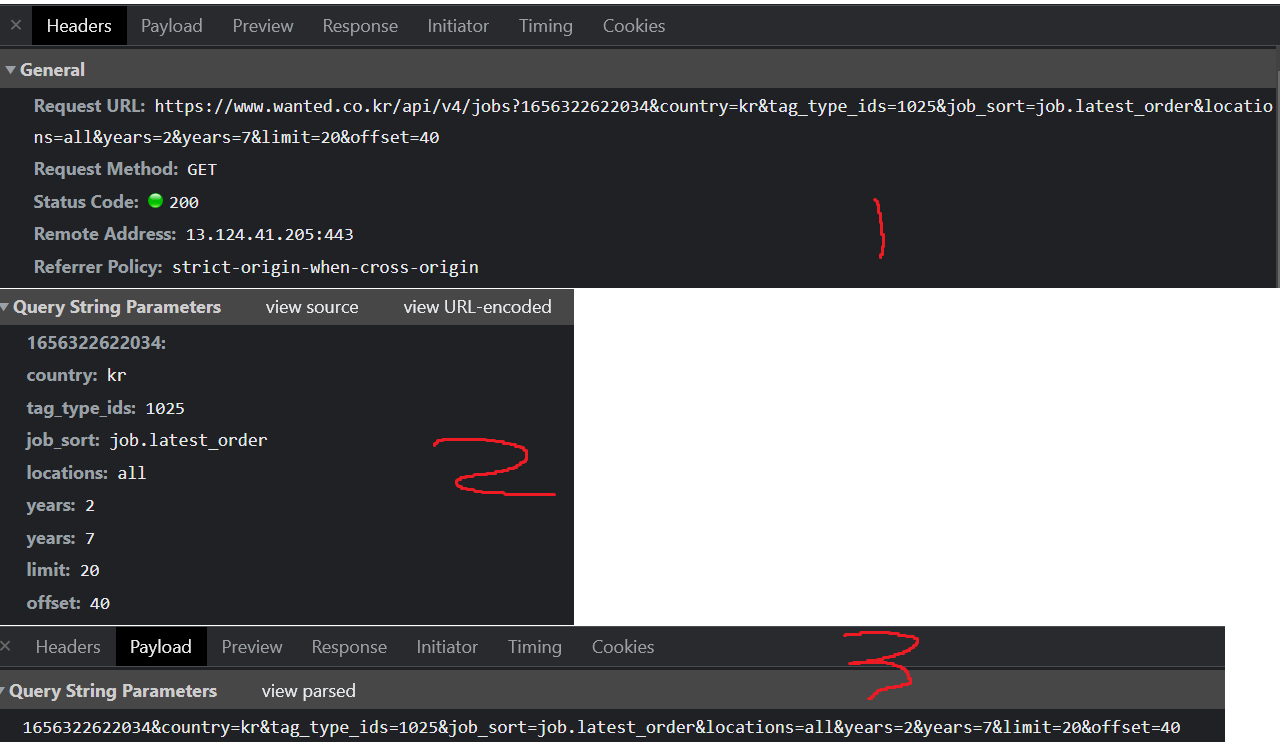
user 가 server에 header와 payload의 형식으로 request 하면
사진3, 4번의 데이터를 user에게 전송해 웹으로 보여준다.

2번은 user와 server의 상호작용 로그
이 로그를 살펴보면 웹의 데이터가 json 형식으로 존재함을 알 수 있다. 위의 이미지 4번
json 안에는 각 게시물의 id와 제목이 존재한다.

그리고 각 게시물은 wanted.co.kr/wd/{고유id}의 형식이므로 게시물의 id로 url을 접근 할 수 있다.
# 게시물 id list
id_list= [1,2,3,]
for id in id_list:
url = f'wanted.co.kr/wd/{id}'
response = 크롤링요청(url)
이제 원하는 게시물들의 id를 모두 수집해야 하는데
네이버의 경우 게시물이 버튼으로 1부터 10, 11부터 20 이런 형식으로 존재하지만

원티드는 쭉 내리면 계속 새로 업데이트 되는 형식(동적웹페이지)이었다.
f12 개발자모드를 활성화 한 상태로 웹을 쭉 내려보겠다.

jobs?로 시작하는 request가 계속 생긴다.
우리는 이게 새로운 json형식의 게시물 data라는 것을 알 고 있다.
이제 payload를 통해서 계속 새로 생기는 request의 쿼리를 알아보겟다.

limit : 게시물의 수
offset : 게시물의 시작 index
ex) limit = 100 , offset = 30
>>>> 30번부터 130번까지의 100개의 게시물의 data
이렇게 예상할 수 있다.
쿼리에 있는 tag_type_ids, job_sort, years 는 직접 웹을 통해서 상호작용해보자

예상던대로 웹에서 선택지를 입력하니 서버에 요청하는 쿼리가 바뀐다.
경력과 직군을 변경하며 쿼리를 분석한다.

이제 코드를 짜기 위해서 필요한 prams를 알아보자
2번 payload에서 view source를 누르면 3번이 나온다.
http://www.wanted.jobs/api/v4/jobs?
이 부분이 원티드 사이트에 api를 요청하는 url이다.
url에 params로 2번사진을 dict 형식으로 넣어주겠다.
def crawl_id(limit=100,offset=0):
url = 'http://www.wanted.jobs/api/v4/jobs?'
params ={1656232918453:'', #사용자번호?
'country': 'all',
'tag_type_ids': 873, #직무 카테고리 고유 id
'job_sort': 'job.latest_order', #최신순 정렬
'locations': all,
'years': -1, #경력 이상
'years': -1, #경력 이하 경력상관없이 검색하려면 -1
'limit': limit, #한 번에 조회 가능한 수 (최대100)
'offset': offset} #조회할 게시물의 첫 index ex) limit=100 offset=10 => 10번게시물부터 110번게시물까지 크롤링
#서버에 url과 쿼리로 요청
r = requests.get(url,
params = params)
#요청한 데이터 json포멧으로 변환
r = r.json()
#json포멧 데이터중 id컬럼만 추출
id_list = [i['id'] for i in r['data']]
return id_list3번을 f-string을 통해서 따로 넣어주어도 된다.
f'http://www.wanted.jobs/api/v4/jobs?/1656322622034&country={}&tag_type_ids={}&job_sort={}&locations={}&years={}&years={}&limit={}&offset={}'
중간점검:
1. 웹페이지를 내릴때마다 게시물이 업데이트된다.
2. limit과 offset쿼리를 통해서 index 기준으로 게시물id를 수집 할 수 있다.
3. year경력 country국가 tag_type_ids직군 location지역을 통해서 필터링 할 수 있다.
#의사코드
id_list= []
for id in id_list:
url = f'wanted.co.kr/wd/{id}'
crawl_job(url)이렇게 해서 각 게시물에 접근해서 데이터를 요청한다.
def crawl_job(id_list):
df_list = []
for id in id_list:
url = f'https://www.wanted.jobs/api/v4/jobs/{id}?1656259528432'
r = requests.get(url)
r = r.json()['job']
#1개의 게시물 크롤링할때마다 데이터프레임에 append 또는 concat하는것보다
#list에 append하고 마지막에 한번에 concat하는게 속도가 더 빠르다
df_list.append(pd.json_normalize(r))
df = pd.concat(df_list, ignore_index=True)
return df
한번에 크롤링을 할 수 없는 이유는
def crawl_id():
url = 'http://www.wanted.jobs/api/v4/jobs?'
params ={1656232918453:'',
'country': 'all',
'tag_type_ids': 873, #직무 카테고리 고유 id
'job_sort': 'job.latest_order', #최신순 정렬
'locations': all,
'years': -1, #경력 이상
'years': -1, #경력 이하 경력상관없이 검색하려면 -1
'limit': 10, #한 번에 조회 가능한 수 (최대100)
'offset': 10} #조회할 게시물의 첫 index ex) limit=100 offset=10 => 10번게시물부터 110번게시물까지 크롤링
#url과 params(쿼리)로 request요청
r = requests.get(url,
params = params)
#request를 json형식으로 받는다
r = r.json()
#json을 dataframe으로
df = pd.json_normalize(r['data'])
return df이 코드에서 limit 부분을 101이상으로 request하면 서버에서 404에러를 리턴한다.
모든 id를 수집하기 위해
limit =100 -> err -> limit=10 -> err -> limit=1
try except 문을 통해서 100개씩 시도
에러발생시 10 -> 1개씩 요청하는 코드 작성.
# 최초 코드
offset=0
while True:
try:
crawl_id(limit = 100,offset)
offset+=100
except:
while True:
try:
crawl_id(limit = 10,offset)
offset+=10
except:
while True:
try:
crawl_id(limit = 10,offset=0)
except:
return
def get_all_ids():
ids = []
limit = 100
offset = 0
while True:
try:
new_ids = crawl_id(limit, offset)
if not new_ids: #
break
ids.extend(new_ids)
offset += limit
except Exception as e:
if limit > 1:
limit //= 10
else:
break
return ids
트러블슈팅:
처음에는
def crawl_job(id_list):
df_list = []
for id in id_list:
url = f'https://www.wanted.jobs/api/v4/jobs/{id}?1656259528432'
r = requests.get(url)
r = r.json()['job']
#1개의 게시물 크롤링할때마다 데이터프레임에 append 또는 concat하는것보다
#list에 append하고 마지막에 한번에 concat하는게 속도가 더 빠르다고 함
df_list.append(pd.json_normalize(r))
df = pd.concat(df_list, ignore_index=True)
#단일 게시물을 크롤링해서 concat하다보니 index가 모두 0이므로 reset_index
return df이 코드를
def crawl_job(id_list):
df = pd.DataFrame()
for id in id_list:
url = f'https://www.wanted.jobs/api/v4/jobs/{id}?1656259528432'
r = requests.get(url)
r = r.json()['job']
df = pd.concat([df,pd.json_normalize(r)],axis=0)
#단일 게시물을 크롤링해서 concat하다보니 index가 모두 0이므로 reset_index
return df.reset_index(drop=True)이렇게 짰었는데

결국 12시간이 넘어 코랩에서 세션만료가 되었습니다.
그래서 한번에 다 크롤링하지말고 id를 100개씩 크롤링을 했더니
100개당 86초가 걸렸습니다
총 게시물이 2200개 = 100 * 22
22 * 86 = 1,892초= 31.5분
데이터 프레임에 담는 과정에서 점점 쌓일수록 concat할 때 무거운 데이터프레임을 계속 불러와서 concat해야하니 속도가 O(nlogn)으로 느려지지 않을까? 라고 의심했습니다.
데이터프레임 concat append 속도차이 에 대해 알아보다가
https://aliencoder.tistory.com/42
[python] pandas의 Dataframe과 list의 삽입 수행 속도 차이
30만 개 정도의 데이터를 Dataframe을 이용해 append 연산을 하는 작업을 수행하다 비정상적으로 느리게 동작하는 것을 발견했다. 아무리 느린 파이썬이라 해도 이 정도로 삽입 연산이 느린 것은 잘
aliencoder.tistory.com
이 글을 보고 list에 모두 담아서 마지막에 dataframe으로 만드는게 더 빠르다는것을 알게 되었습니다.
추후 개선사항:
tag_type_ids별 어떤 직군인지 직접 웹을 만지면서 적어두어야함 그래야 원하는 직무만 크롤링 가능
2024년도에 다시 이 글을 본 시점으로는
내부 변수를 사용하기 위해 class 로 구현 후
id_list의 개수에 비례해서 청크를 나눠 병렬로 요청을 하면 금방 끝나지 않을까 싶습니다.
최종코드
import time
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
def crawl_id(limit=100,offset=0):
url = 'http://www.wanted.jobs/api/v4/jobs?'
params ={1656232918453:'', #사용자번호?
'country': 'all',
'tag_type_ids': 873, #직무 카테고리 고유 id
'job_sort': 'job.latest_order', #최신순 정렬
'locations': all,
'years': -1, #경력 이상
'years': -1, #경력 이하 경력상관없이 검색하려면 -1
'limit': limit, #한 번에 조회 가능한 수 (최대100)
'offset': offset} #조회할 게시물의 첫 index ex) limit=100 offset=10 => 10번게시물부터 110번게시물까지 크롤링
#서버에 url과 쿼리로 요청
r = requests.get(url,
params = params)
#요청한 데이터 json포멧으로 변환
r = r.json()
#json포멧 데이터중 id컬럼만 추출
id_list = [i['id'] for i in r['data']]
return id_list
def return_id_list():
'''
0번째 게시물부터 100개씩 크롤링 while true
오류발생! => ex) 총 게시물이 321개인데 300개 크롤링 후 다음100개를 크롤링하려했기때문
따라서 재귀호출을 통해 크롤링 수를 100개씩 -> 오류발생! -> 10개씩 -> 오류발생! -> 1개씩 크롤링하는 함수구현
만약 게시물이 321개라면 300개 크롤링 -> 20개 크롤링 - 1개 크롤링 return
'''
id_list=[]
def crawl_all_id(limit=100,offset=0):
try:
while True:
id_list.extend(crawl_id(limit,offset))
offset+=limit
except:
if limit != 1:
return crawl_all_id(limit/10,offset)
crawl_all_id()
return id_list
def crawl_job(id_list):
df_list = []
for id in id_list:
url = f'https://www.wanted.jobs/api/v4/jobs/{id}?1656259528432'
r = requests.get(url)
r = r.json()['job']
#1개의 게시물 크롤링할때마다 데이터프레임에 append 또는 concat하는것보다
#list에 append하고 마지막에 한번에 concat하는게 속도가 더 빠르다고 함
df_list.append(pd.json_normalize(r))
df = pd.concat(df_list, ignore_index=True)
#단일 게시물을 크롤링해서 concat하다보니 index가 모두 0이므로 reset_index
return df
def engineering(df):
drop_col = []
df = df.drop(drop_col,axis=1)
return df
start = time.time()
id_list = return_id_list()
end=time.time()
print(end-start)
df_job = crawl_job(id_list)
end=time.time()
print(end-start)2022-06-29
it 개발 직군 'tag_type_ids': 873을 모두 크롤링 했을때 총 게시물은 2079개
크롤링 시간은
1693.5257630348206
이정도 걸렸습니다.